About the Task
The task you just completed is called the semantic fluency task. In this task, you were presented with a category (i.e., Animals, Occupations, Things at the Beach, or Things in a Classroom) and asked to list as many members of that category as you could think of in one minute (e.g., dog, cat, rat, squirrel). It is a common psychological battery task used to assess memory, and it can help scientists better understand how humans search through their mental lexicons. In the semantic fluency task, individuals tend to produce items in related clusters– for example, dog and cat are both Pets. We can also use other types of information, such as how words sound, to find the next item (e.g., cat and rat sound alike). Take a moment to think about the list you produced – can you find any of these clusters?
Our research, funded by the National Science Foundation (NSF) (Award Numbers 2235362 and 2235363), seeks to understand how humans represent and find words in memory. We have compiled data from 1200+ individuals, which is, to date, the largest set of semantic fluency data available. We have also collected data from multiple categories. Animals is widely studied, but we are also interested in other types of categories. For example, we examined how people find words that belong to the same theme, but are not necessarily categorically related, such as Things in a Classroom.
Where did this data come from?
The data set was collected online by advertising through social media and recruiting from an online platform called Prolific. Demographic information about our sample can be found below.
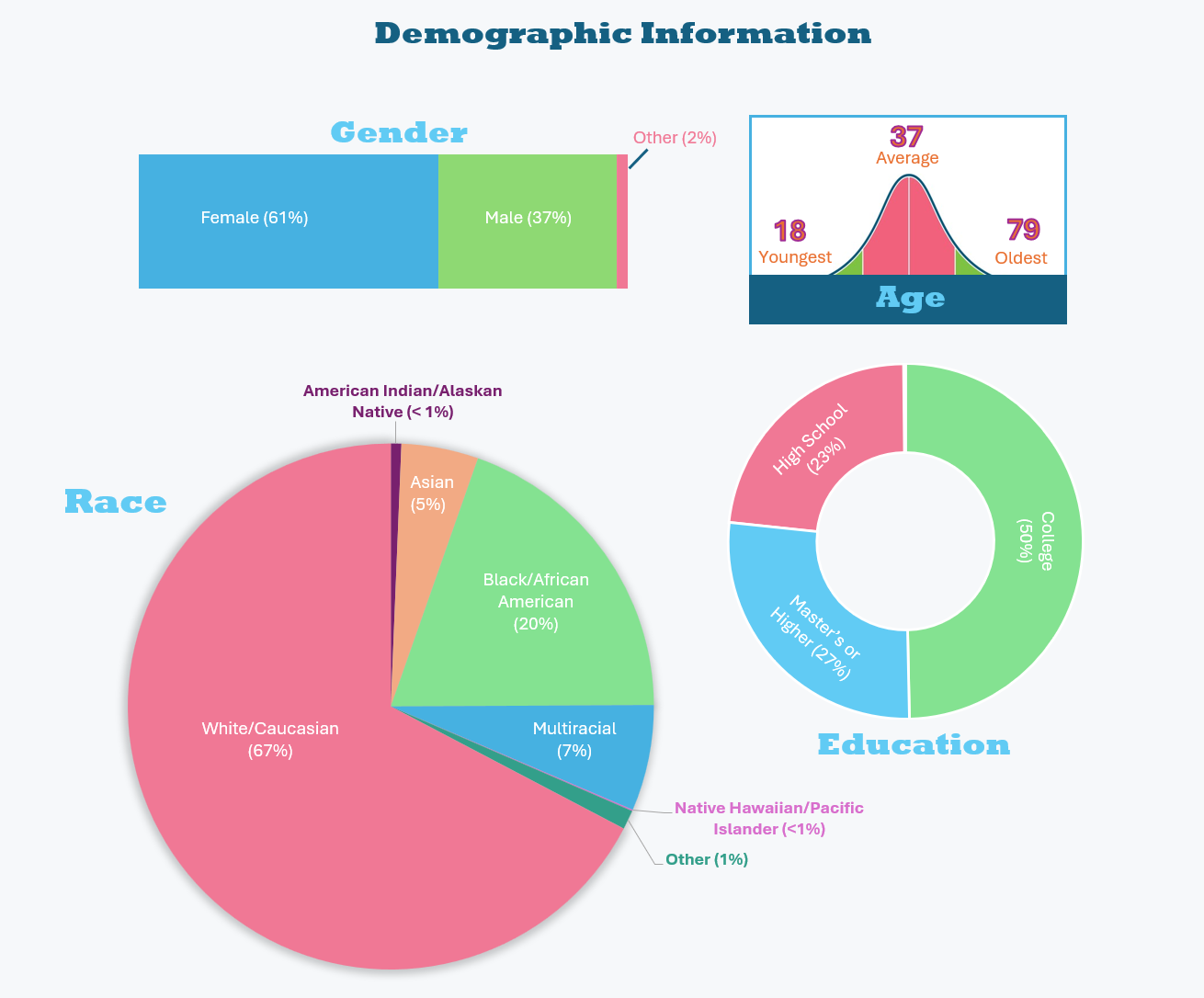
What have you found?
Our research has shown that:
- Categories have distinct structures, and we search through them differently
- It's easier to find words in categories with clear hierarchies and sub-categories
- It's more difficult to find words in other types of categories, and people may draw more on their personal experience to guide search
- Depending on the specific category, using how words sound to guide search can improve performance
For Researchers
Where can I access the data?
The dataset is publicly available for download via the Open Science Framework (OSF).
The data set was collected online from participants on Prolific as well as through social media. The full data set contains fluency lists for 6 categories (Animals, Occupations, Things at the Beach, Things in a Classroom, Excuses for Being Late, and Things to Rescue from a Burning Home).
How can I analyze the data?
Fluency lists can be analyzed for several different patterns, such as clustering behavior, lexical patterns, and individual differences. Our lab has also developed a publicly available Python package and web interface called forager to analyze fluency lists.
Researchers can also use other tools such as SNAFU and SemNA to extract other patterns within fluency lists.
Where can I learn more about this research?
For more information about our research and current papers on this topic, please visit our lab website.